CV的常见评估指标
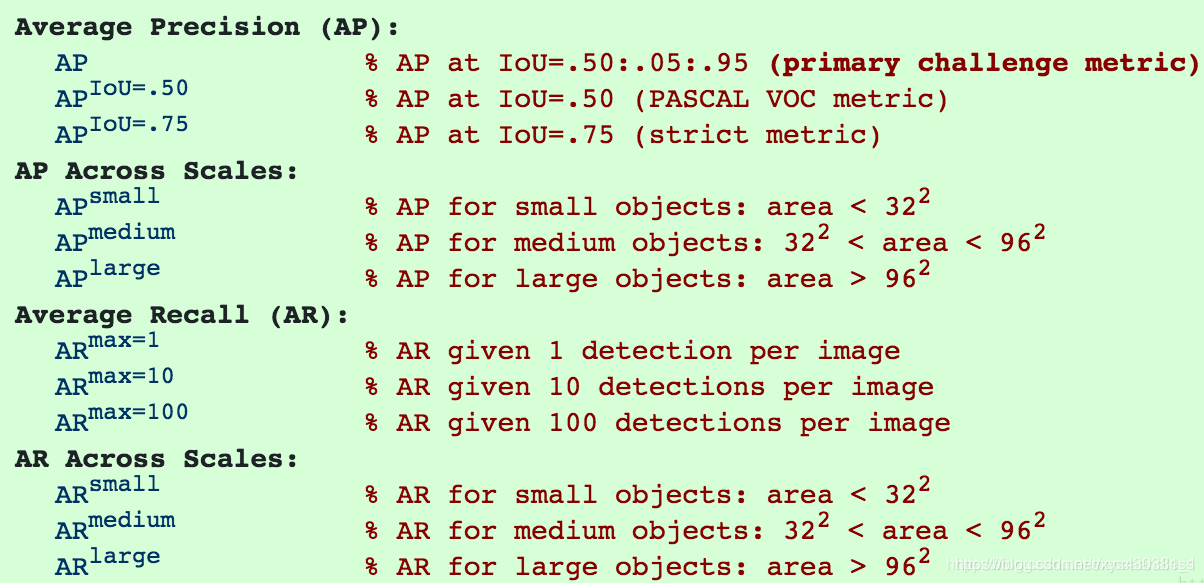
CV的常见评估指标 type: Post status: Published date: 2025/09/16 分类任务通常是识别输入图像属于哪个类别。常见指标包括: Accuracy(准确率) $$ Accuracy = \frac{TP + TN}{TP + TN + FP + FN} $$ 表示模型预测正确的样本占总样本的比例。适合类别分布平衡的情况。 Precision(精确率) $$ Precision = \frac{TP}{TP + FP} $$ 在所有被预测为正样本的结果中,真正为正的比例。关注预测的“正确性”。 主要意义可以理解为:假的东西不能预测为真;当假阳的代价很高时,我们不希望误判。比如垃圾邮件过滤,如果垃圾邮件被漏掉的代价远小于非垃圾邮件被丢入垃圾站。 $$ Recall = \frac{TP}{TP + FN} $$ 在所有真实正样本中,模型成功检出的比例。关注预测的“完整性”。 主要意义可以理解为:真的东西不能预测为假,比如疾病如果阳性被误诊为假阴,可能导致错过治疗。 $$ F1 = 2 \cdot \frac{Precision \cdot Recall}{Precision + Recall} $$ 在需要平衡精确率和召回率时使用。 ROC 曲线 & AUC ROC 曲线展示了不同阈值下 TPR vs. FPR 的变化,AUC 是曲线下面积,衡量模型整体区分能力。 PR 曲线 如果数据集在类别之间大致平衡,AUC 和 ROC 非常适合比较模型。当数据集不均衡时,准确率-召回率曲线 (PRC) 和这些曲线下的面积可以更好地直观比较模型性能。 AP在Precision-Recall曲线的基础上,通过计算每一个recall对应precision的平均值得出,AP的值是曲线下的面积。但实际应用中主要取右侧最大值。 在多类别的目标检测中,每一个类别都可以绘制PR/AP曲线,对应所有AP曲线的则是mAP。 目标检测需要预测物体的位置(边界框)和类别。 IoU(Intersection over Union) $$ IoU = \frac{预测框 \cap 真值框}{预测框 \cup 真值框} $$ 衡量预测框和真实框的重叠程度。通常认为 IoU ≥ 0.5 即为“检测正确”。 mAP(mean Average Precision) 如果IoU阈值=0.5,则为AP@50(意味着只要预测框与真实框有50%重叠就算正确),如果IoU阈值=0.75,则为 AP@75,以此类推 在COCO的AP计算中常见AP[.50:.05:.95]:在 IoU 阈值从 0.50 到 0.95,步长 0.05 共 10 个值上分别计算 AP,然后取平均。 因此,常见的对比方式是: FPS(Frames per Second) 衡量模型推理速度,检测中常用来平衡精度与实时性。 分割任务是逐像素地分类。 Pixel Accuracy(像素精度) 正确分类像素数 / 总像素数。 IoU(或称 Jaccard Index) 用于衡量预测区域与真实区域的重叠程度。 在语义分割和实例分割中使用。 mIoU(mean IoU) 对所有类别的 IoU 取平均,是最常用的分割指标。 Dice 系数(Dice Coefficient / F1 for segmentation) $$ Dice = \frac{2 \cdot |预测 \cap 真值|}{|预测| + |真值|} $$ 对小目标更敏感,常用于医学图像分割。 如图像检索、人脸识别等,需要对候选结果排序。 Top-k Accuracy 如果正确标签出现在前 k 个预测中,即认为正确(常见于 ImageNet)。 Recall@k 前 k 个检索结果中是否包含目标。 mAP@k 检索任务中的平均精度,取前 k 个结果计算。 NDCG(Normalized Discounted Cumulative Gain) 衡量排序结果的相关性与理想排序的接近程度。 在目标检测(尤其是 One-stage 检测器,如 RetinaNet)中,存在一个突出问题: Focal Loss 是在交叉熵损失的基础上加了一个调制因子(modulating factor),用来降低“易分类样本”的损失权重,从而让模型更关注“难分类样本”。 $$ FL(P_t)=-\alpha (1-p_t)^\gamma log(p_t) $$ 聚焦参数解释: 因此,$\gamma$ 控制模型是否更“关注难样本”。 在实践中: https://zhuanlan.zhihu.com/p/479674794 https://zhuanlan.zhihu.com/p/88896868 https://blog.csdn.net/qq_42722197/article/details/128963093 https://hackmd.io/@wayne0509/HkZ6rEZMP#mAP https://developers.google.com/machine-learning/crash-course/classification/accuracy-precision-recall?hl=zh-cn https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc?hl=zh-cn Lin, T. Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980-2988). https://amaarora.github.io/posts/2020-06-29-FocalLoss.htmlCV目标检测指标
1. 常见评价指标
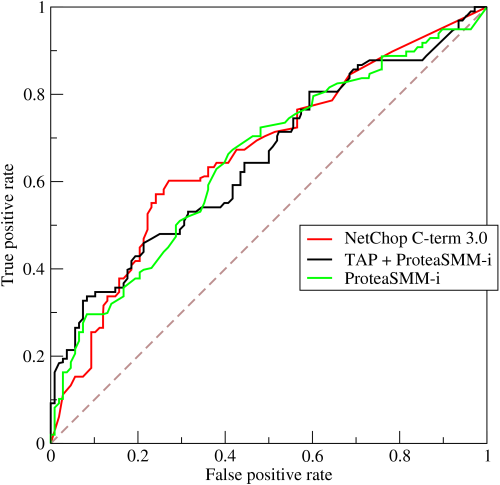
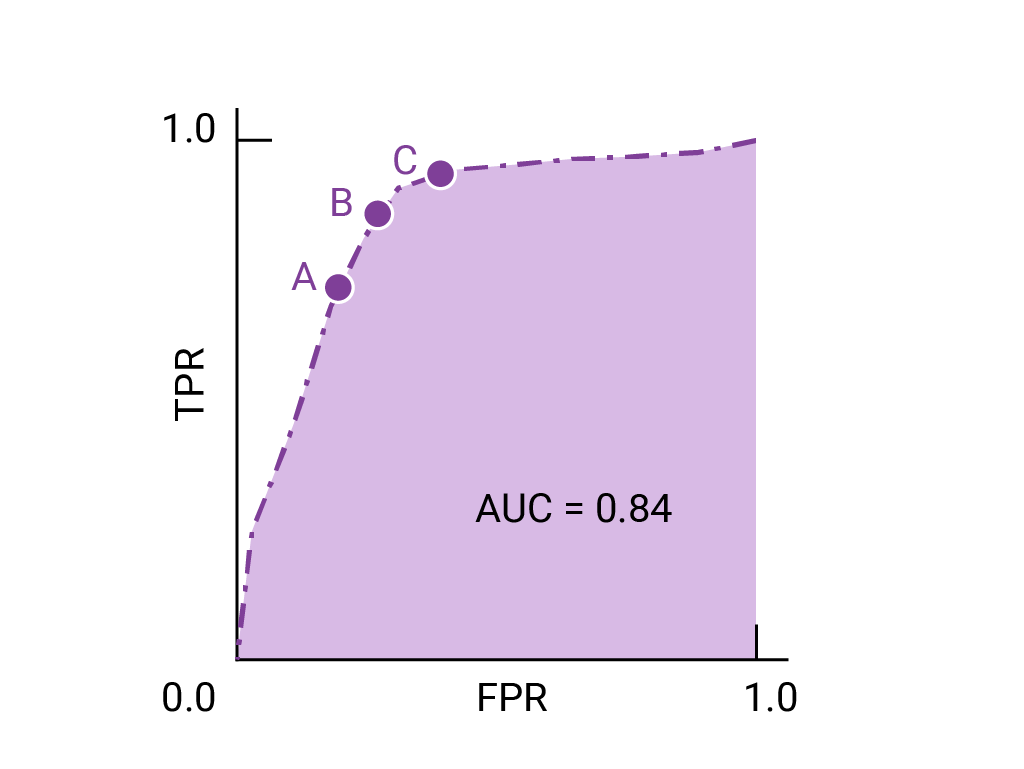

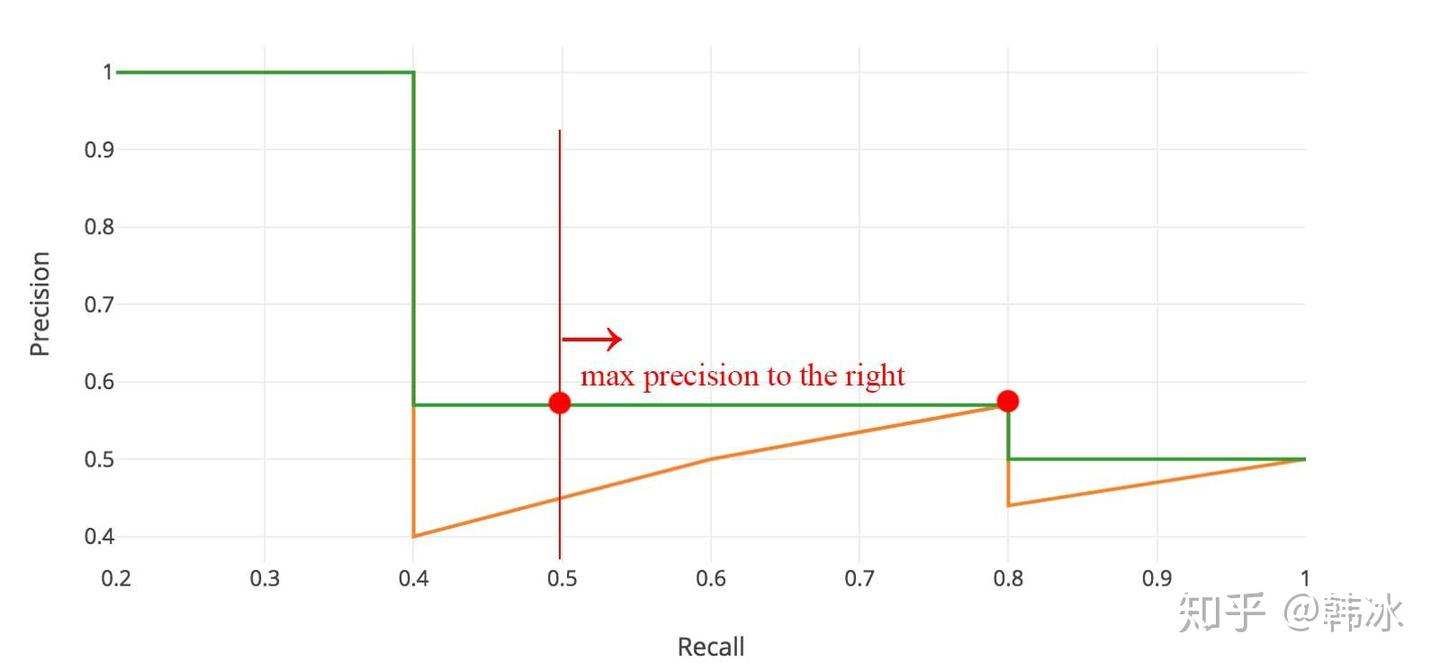
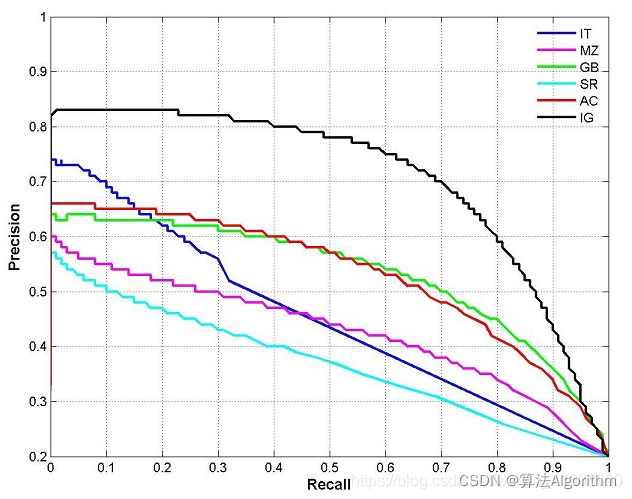
2. 目标检测任务常见指标

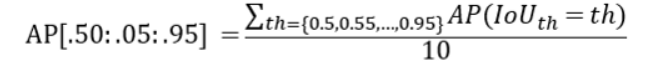
3. 图像分割任务常见指标
4. 检索与排序任务常见指标
5. 一些额外指标
Focal Loss
参考: